ZFS hat ja den Ruf kompliziert zu sein und den unerfahrenen Admin zu Fehlbedienungen mit Datenverlust zu verleiten. 2016 hatte ich das letzte Mal die Platten in meinen NAS (auf Debian) gegen größere Platten ausgetauscht und bei der Gelegenheit die Daten auf ZFS umkopiert. Mich hat dabei vor allem die Sicherheit gegen “bit rot” und “silent corruption” gereizt – ich würde ungerne Bilder meiner Fernreisen verlieren. Nun ist ZFS sehr mächtig, für den üblichen Anwendungsfall – 2 Platten in Raid1 – ist das ganze aber überschaubar. Das läßt man zumeist solange laufen, bis die Platten zu klein geworden sind. Dann ist es bei vernünftiger Planung eh so weit, das man neue Platten kaufen muß, weil die alten lange genug gelaufen sind.
ZFS Pool erstellen
Wenn man sich an die Empfehlung hält, ZFS nur ganze Platten und nicht Partitionen anzubieten, ist das ganze sehr einfach:
- maximale RAM Nutzung limitieren!
/etc/modprobe.d/zfs.conf: # yes you really DO have to specify zfs_arc_max IN BYTES ONLY! # 16GB=17179869184, 8GB=8589934592, 4GB=4294967296, 2GB=2147483648, 1GB=1073741824, 500MB=536870912, 250MB=268435456 # options zfs zfs_arc_max=4294967296 - Platten IDs feststellen, gpt Partitionstabelle erzeugen:
ls -l /dev/disk/by-id parted /dev/disk/by-id/id1 mklabel gpt - Pool “zpool1” erzeugen:
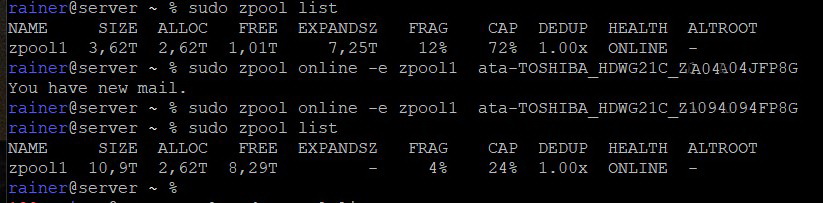
zpool create -o ashift=12 zpool1 mirror /dev/disk/by-id/id1 /dev/disk/by-id/id2 zfs set atime=off zpool1 zfs set dedup=off zpool1 zpool list - Mountpoint erstellen:
zfs create -o mountpoint=/home zpool1/home
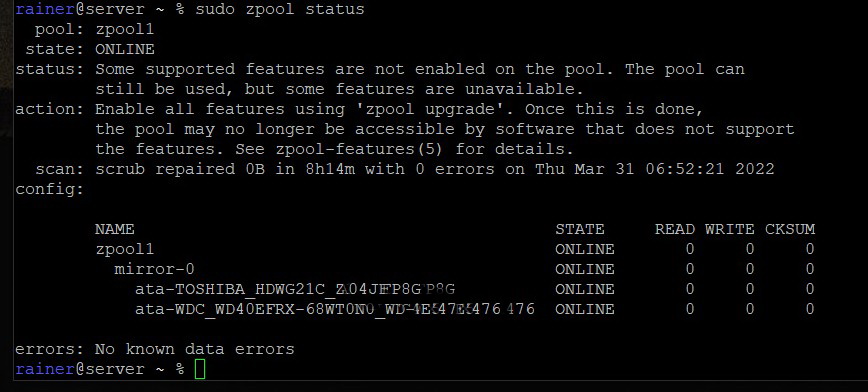
Das war es dann auch schon. Gelegentlich ein “zpool scrub zpool1” laufen lassen. Ich hatte zuerst ein Standard-PC Board in meinen Server ohne RAM Parity laufen und hatte nie auch nur ein Byte beim Scrub zu korrigieren. Vor etwa 2 Jahren habe ich dann die Hardware ausgetauscht gegen ein Serverboard mit ECC-RAM (Supermicro X11SCL-IF) gemäß dem Artikel der ct 18/2020. Ich bin dann auch voll in die Probleme mit der NVM-SSD gelaufen, mit zahlreichen Abstürzen in unregelmäßigen Abständen. Der Rechner war dann immer nur mit hartem Ausschalten wieder zum Laufen zu bewegen. In keinem dieser Fälle aber hatte ZFS hinterher angefangen zu Resilvern oder im Scrub beschädigte Daten zu melden!
Platten tauschen
Inzwischen war ich bei einer Belegung von etwa 75% angelangt, irgendwann sinkt dann die Schreibperformance. Das wäre zwar nicht so tragisch bei meiner Anwendung, aber in der jetzigen Zeit werden Plattenpreise bestimmt nicht sinken. Also zwei neue Platten bestellt und die erste eingebaut.
- wie oben Platten ID feststellen, gpt Partitionstabelle erzeugen:
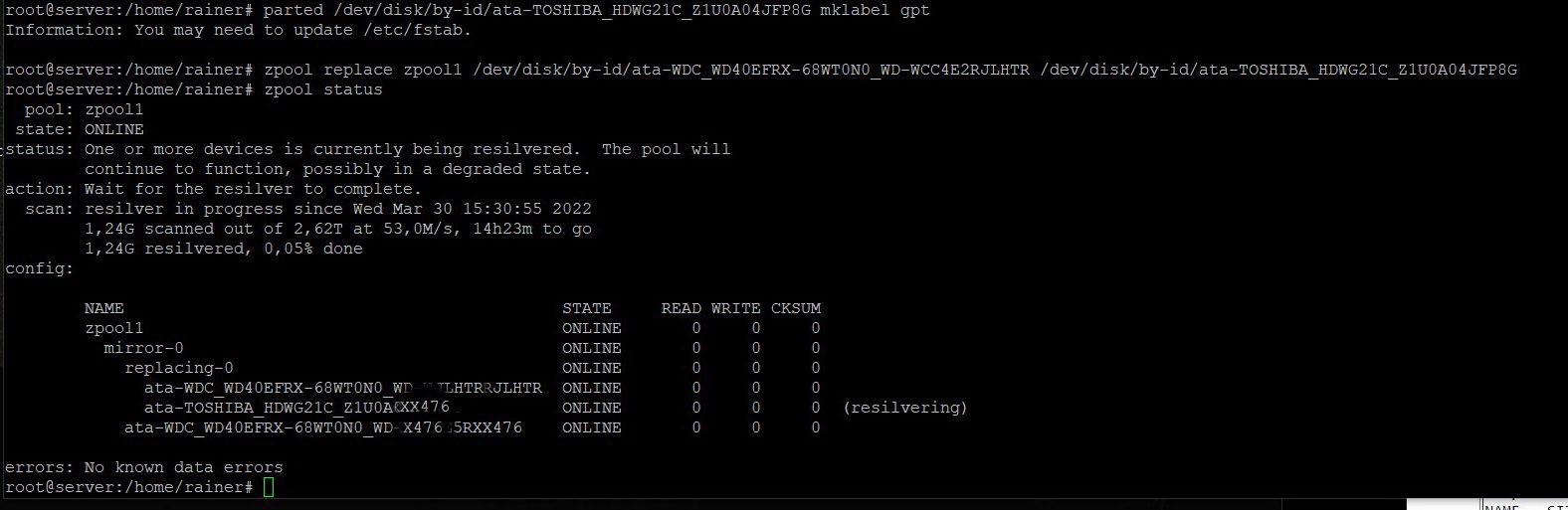
ls -l /dev/disk/by-id parted /dev/disk/by-id/id1 mklabel gpt zpool replace zpool1 /dev/disk/by-id/id_alt /dev/disk/by-id/id_neu
 Nach komplettem Neuaufbau erst mal ein paar dutzend GByte schreiben und Scrub starten: (“Außerdem sollten Sie zwischen dem Austausch von Festplatten den Befehl zpool scrub ausführen, um sicherzustellen, dass die Austauschgeräte ordnungsgemäß funktionieren und Daten fehlerfrei geschrieben werden”) s. ZFS-Doku
Nach komplettem Neuaufbau erst mal ein paar dutzend GByte schreiben und Scrub starten: (“Außerdem sollten Sie zwischen dem Austausch von Festplatten den Befehl zpool scrub ausführen, um sicherzustellen, dass die Austauschgeräte ordnungsgemäß funktionieren und Daten fehlerfrei geschrieben werden”) s. ZFS-Doku
- Zweite Platte einbauen und genauso verfahren. Nach dem folgenden Befehl müßte der Speicherplatz sich automatisch vergößern:
zpool set autoexpand=on zpool1
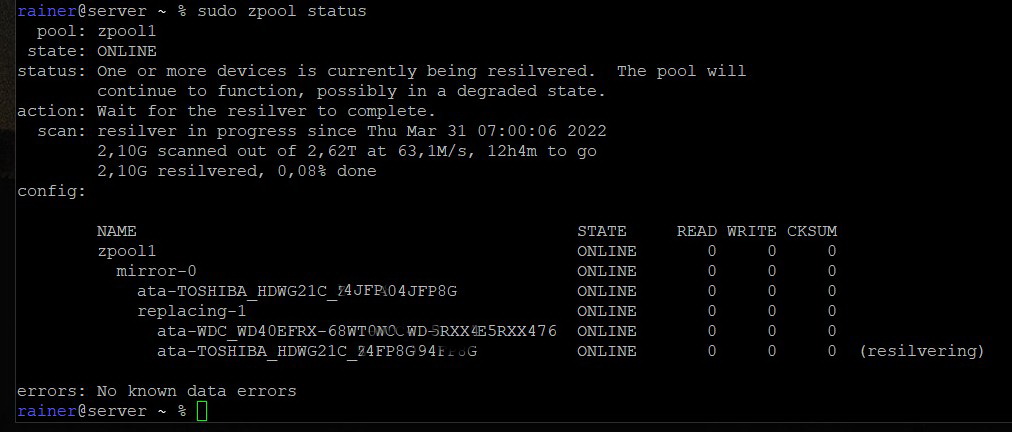
Bei mir war das nicht der Fall, ich vermute das liegt daran das ich noch eine ältere Zpool-Version habe. Also muß man für beide Platten noch einmal folgendes eingeben:
zpool online -e zpool1 disk_id1
zpool online -e zpool1 disk_id2